<알고리즘과 문제 해결 패턴>
알고리즘이란?
특정 작업을 달성하기 위한 혹은 문제를 해결하기 위해 수행해야 하는 일련의 과정이나 단계를 의미한다.
알고리즘 문제를 풀기 위해,
1. 문제 해결을 위한 계획을 생각해본다.
2. 일반적인 문제 해결 패턴을 파악하고 익힌다.
<문제 해결 전략>
1. 문제의 이해
① 내 자신의 말로 문제를 다시 파악하고 설명해보도록 한다.
② 문제에 사용되는 입력값들은 무엇인지 파악한다.
③ 문제의 해답으로 나와야하는 출력값들은 무엇인지 파악한다.
④ 입력값이 출력값을 결정하게 되는지, 문제를 해결할 정보가 충분히 주어졌는지 생각해본다.
⑤ 문제로 제시된 데이터들 중 중요한 부분들이 무엇인지, 어떻게 분류해야 할지, 어떤 이름(용어)을 붙일지 생각해본다.
ex) 두 수를 가지고 그들의 총합을 반환하는 함수를 작성하라.
① 내 자신의 말로 문제를 다시 파악하고 설명해보도록 한다. => 덧셈 실행
② 문제에 사용되는 입력값들은 무엇인지 파악한다. => 정수? 실수? 큰 수들에 대해서 문자열은 어떤지?
③ 문제의 해답으로 나와야하는 출력값들은 무엇인지 파악한다. => 정수? 실수? 문자열?
④ 입력값이 출력값을 결정하게 되는지, 문제를 해결할 정보가 충분히 주어졌는지 생각해본다. => 만약에 수가 하나만 입력된다면? 0을 더하나? 아님 undefined나 null을 반환하나?
⑤ 문제로 제시된 데이터들 중 중요한 부분들이 무엇인지, 어떻게 분류해야 할지, 어떤 이름(용어)을 붙일지 생각해본다. => num1, num2, sum
2. 구체적 예제들
예시는 문제를 이해하는 데에 도움을 주고, 해답에 대한 온전성을 체크할 수 있게 해준다.
예시를 알고 있다면 구현한 작업을 확인할 수 있을 뿐 아니라 예시를 적용하면서 더 많은 정보를 얻을 수도 있다.
cf. User Stories - 사용자에 의해 주어진 입력값을 제외하고 어떤 결과가 일어날지 고려함 , Unit Tests(단위 검사) - 더 작은 기능에 대해 무엇이 어떻게 작동해야하는지 그 틀을 잡는 데에 사용됨
① 간단한 예시(입력과 출력)를 작성해보며 시작한다.
② 쉬운 예시들로부터 더 복잡한 예시들로 진행해본다.
③ 비어있거나 유효하지 않은 입력값이 주어진 예시를 생각해본다.
ex) 문자열 입력받아 각 문자의 수를 반환하는 함수를 작성하라.
① 간단한 예시(입력과 출력)를 작성해보며 시작한다. => 문제를 잘 이해하는지 몇 가지 간단한 예시를 떠올려보기. => 배열이나 다른 데이터 구조가 아닌 객체가 반환되어야 한다는 것을 알 수 있음 => 모든 문자들을 키로 갖고, 그 값은 0으로 초기화할지?
② 쉬운 예시들로부터 더 복잡한 예시들로 진행해본다. => 숫자와 문자, 공백, 기호가 들어있든지 혹은 대소문자가 함께 들어있는 경우에는 어떻게 할지?
③ 비어있거나 유효하지 않은 입력값이 주어진 예시를 생각해본다. => 사용자가 문자열이 아닌 숫자나 객체나 null을 전달(입력)한다면
3. 세부 분석
어떤 단계를 밟아 문제를 풀 것인지 기본적인 구성 요소를 가지고 써본다.
종이나 화이트보드에 몇 가지 예시를 작성하면서 함수의 구조를 잡아 나간다.
4. 해결 또는 단순화
5. 되돌아 보기와 재구성(refactor)
빈도 카운터(frequency counters), 투 포인터(two-pointer), 분할정복(divide and conquer) 등의 문제 해결법을 비교하고 대조해보며 해당 문제에 최적한 방법이 무엇인지 생각해보고 선택해 적용한다.
<문제 해결 패턴>
- 분할 정복(Divide and conquer) : 배열, 문자열, 연결 리스트, 트리 등의 큰 데이터셋을 작은 덩어리로 나눈 하위 데이터셋을 가지고 어떤 과정을 반복한다. 이 방식은 시간 복잡도를 엄청나게 줄여준다. 대표적으로 퀵 정렬과 병합 정렬, 이진 탐색의 알고리즘이다. 배열을 순차적으로 탐색하지 않고, 작은 조각으로 세분하여 어느 쪽으로 이동해 작업할 지 결정한다.
ex) 주어진 정렬된 정수 배열과 수 하나를 입력받아 그 수가 배열에서의 인덱스를 반환하고, 없다면 -1을 반환하는 함수를 작성하라.
search([1, 2, 3, 4, 5, 6], 1) // 0
search([1, 2, 3, 4, 5, 6], 4) // 3
search([1, 2, 3, 4, 5, 6], 7) // -1


- 탐욕 알고리즘(Greedy algorithms)
- 빈도 카운터(Frequency counter) : JS의 객체를 이용해 배열이나 문자열(선형 구조)의 내용을 분석하여 다양한 값과 빈도를 수집한다. 각각의 객체의 형태를 통해 주어진 데이터와 입력값이 서로 비슷한 값으로 구성되어 있는지, 서로의 애너그램인지 확인할 때, 값이 다른 값에 포함되는지 여부를 비교하거나, 데이터를 입력값이나 두 개 이상의 빈도나 특정하게 발생하는 빈도와 비교할 때 유용하다.
ex) 2개의 배열을 허용하는 same이라는 함수를 작성하라. 배열의 모든 값이 두 번째 배열에 해당하는 값의 제곱의 값들로 가지고 빈도수도 같으면 참을 반환하라.
same([1, 2, 3], [4, 1, 9]) // true
same([1, 2, 3], [1, 9]) // false
same([1, 2, 1], [4, 4, 1]) // false (같은 빈도수가 아니라서)

!! indexOf의 기능 자체가 전체 배열을 반복하거나 중첩된 반복문 전체를 잠재적으로 반복하므로,
위에서 for 문 안에서 indexOf를 사용한다고 한다면, O(n^2)의 시간복잡도가 되므로 바람직하지 못한 코드가 된다 !
위에서는 indexOf를 사용함으로써 arr1의 길이만큼 arr2를 순회하며 index를 찾게 되므로 중첩문같은 상황이 되는 것이다.

첫번째 배열에 루프를 적용하여 두번째 배열의 하위 루프에서 각 값을 확인하는 앞선 방식대신 => O(n^2)
위의 코드처럼 각 배열에 한번씩 개별적으로 루프를 적용한다 ! => O(n) <= 대략 3n
애나그램(Anagrams)
ex) 두 개의 문자열을 입력받아 서로의 애나그램(문자열의 문자들을 재배열한 것)이면 참을 반환하라.
validAnagram(' ', ' ') // true
validAnagram('abb', 'bba') // false
validAnagram('anagram ', 'nagaram') // true
validAnagram('rat', 'art') // true
validAnagram('creepy', 'creep') // false
validAnagram('quite', 'quiet') // true
validAnagram('texttwisttime', 'timetwisttext') // true

cf. for of 문은 새 변수에 객체의 키의 값을 저장하고, for in 문은 새 변수에 객체의 키를 저장한다 !

!! 애나그램 자체가 두 객체의 정보가 같아야 하므로, 위의 내 코드처럼 객체를 두 개 따로 만들지 않고 하나의 객체로만 만들어서 비교해도 되겠다 !
- 다중 포인터(Multiple Pointers) : 인덱스나 위치에 상응하는 값들이나 포인터들을 만들어 배열이나 문자열, 이중 연결 리스트, 단일 연결 리스트와 같은 선형구조에서 특정 조건에 따라 만들어진 시작과 끝 지점이나 중간지점을 향해 이동시키며 공간 복잡도를 최소화하여 매우 효과적으로 문제를 풀어낸다. 보통은 투-포인터라고 두 가지의 참조값(포인터)를 사용한다.
ex) 정렬된 정수 배열을 입력받아 합이 0이 되는 첫번째 쌍을 반환하거나 존재하지 않으면 undefined를 반환하는 함수를 작성하라.
sumZero([-3, -2, -1, 0, 1, 2, 3]) // [-3, 3]
sumZero([-2, 0, 1, 3]) // undefined


위에서는 두 개의 포인터로 왼쪽 끝과 오른쪽 끝에서 가운데로 이동하는 방식이었지만, 다른 방식도 있다.
ex) 정렬된 정수의 배열을 입력받아 그 배열 안의 고유한 수의 개수를 반환하는 함수를 작성하라.
countUniqueValues([1, 1, 1, 1, 1, 1, 2]) // 2
countUniqueValues([1, 2, 3, 3, 4, 4, 4, 5, 12, 14, 14]) // 7
countUniqueValues([ ]) // 0
countUniqueValues([-3, -1, -1, 0, 5]) // 4

// function countUniqueValues(arr){
// let left = 0
// let right = 1
// while(right < arr.length) {
// if(arr[left] === arr[right]) right += 1
// else {
// left += 1
// arr[left] = arr[right]
// right += 1
// if(right === arr.length - 1) return left + 1
// }
// }
// }
// countUniqueValues([-3, -2, 0, 3, 3, 5, 6, 7, 7, 10])
※ 정답이 안 나왔던 나의 문제 풀이.
틀렸던 이유 ㅡ
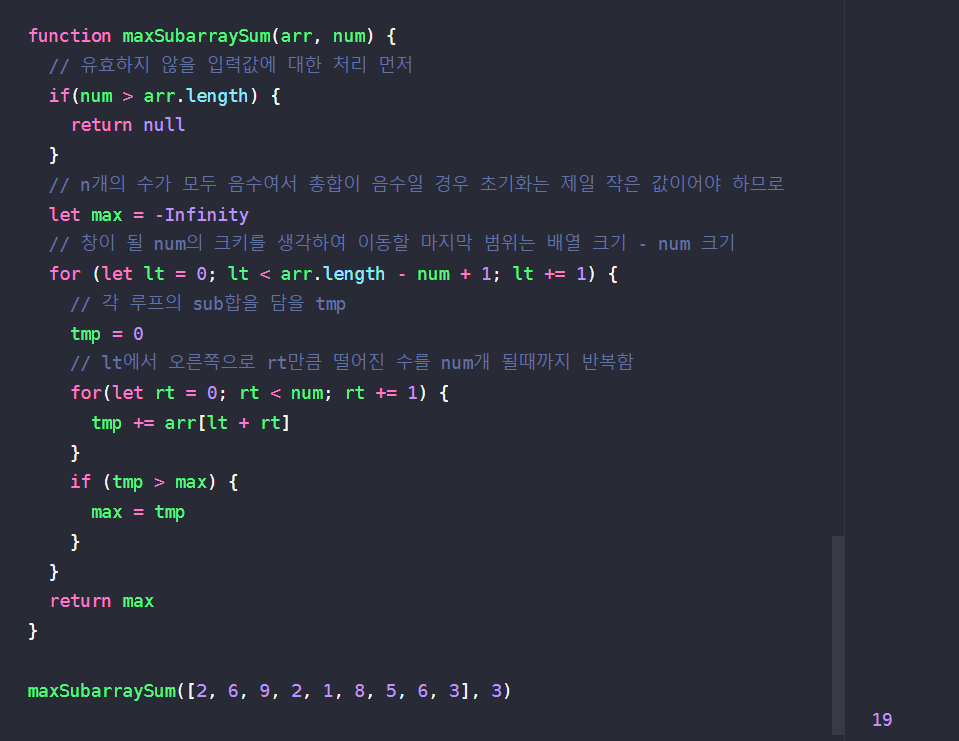
- 슬라이딩 윈도우(Sliding window) : 어떤 배열이나 숫자를 위치를 바꿔가며 창(window)과 같은 일정 부분을 만들어 문제 해결에 접근하는 방법으로, 어떤 조건에 따라 이 창은 증가(이동)하거나 끝나거나 새로이 만들어지면서 배열이나 문자열(/ 큰 데이터 set) 안에서의 하위 집합을 찾는 경우에 유용하게 사용되는 방법이다. 여기에서의 창(window)은 단일 변수, 하위 배열, 또는 다른 문자열도 될 수 있다 !
ex) 입력받은 정수 배열에서 n개의 연속된 수의 합 중 최대합을 찾아 반환하는 함수를 작성하라.
maxSubarraySum([1, 2, 5, 2, 8, 1, 5], 2) // 10
maxSubarraySum([1, 2, 5, 2, 8, 1, 5], 5) // 21
maxSubarraySum([ ], 3) // null

- 동적 프로그래밍(Dynamic Programming)
- 백트래킹(Backtracking)
'KDT TIL Note > 알고리즘' 카테고리의 다른 글
| [알고리즘 자습] 대표적인 데이터 구조: 해쉬 테이블(Hash Table) (0) | 2022.12.23 |
|---|---|
| [알고리즘 자습] 빅오 표기법(big O notation), 로그(Logarithms) (0) | 2022.11.25 |